Aggregated Intelligence – A Multi-LLM Response Engine for Synthesized Truth & Thought Diversity
The Core Idea
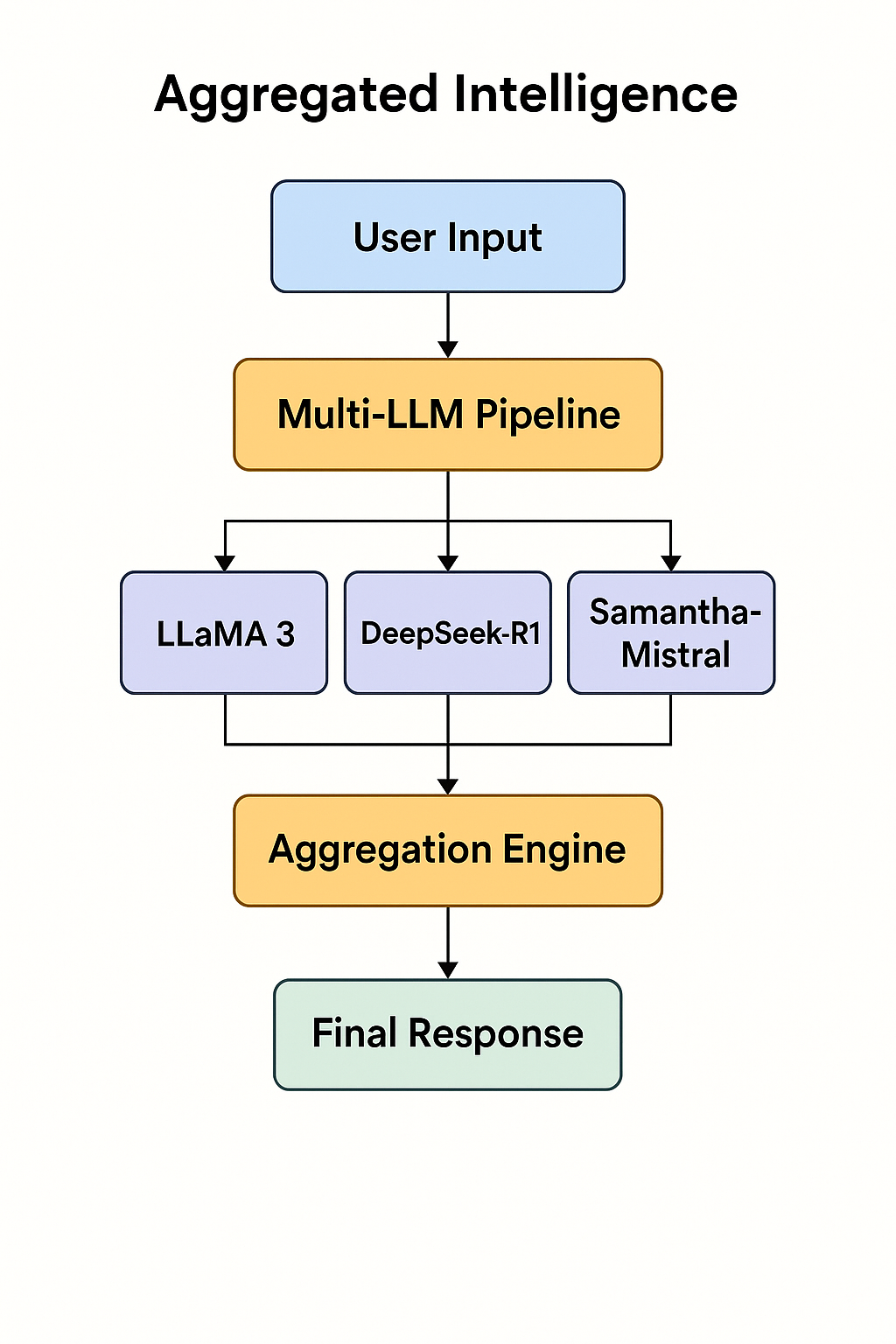
Aggregated Intelligence is a system that leverages multiple large language models (LLMs) to answer a single user prompt. Instead of relying on one AI’s output, the system queries several distinct models (e.g., LLaMA-3, DeepSeek, Samantha-Mistral), compares their responses, and intelligently aggregates the best parts into a final, high-quality answer.
The result? A more accurate, nuanced, and trustworthy AI experience that is backed by redundancy, perspective diversity, and model-level dialogue.
Problem Statement
Current AI systems typically rely on a single model pipeline. This presents several risks:
Hallucinations or factual errors go unchecked. Biases from a model’s training corpus can dominate the output. Users cannot compare alternate perspectives unless they manually test other models.
How It Works
Input: User submits a question or prompt. Model Invocation: The system routes the input to 3+ diverse LLMs (e.g.: LLaMA-3:latest DeepSeek-R1 Samantha-Mistral These may be open-source, proprietary, or specialized models.) Response Aggregation Engine: Compare & contrast outputs line-by-line or semantically. Extract best insights, flag contradictions, and harmonize tone. Use either a rule-based engine or a meta-model trained to evaluate, rank, and synthesize LLM outputs. Final Output: A clean, synthesized, user-facing answer. Optional: toggle to view individual model responses, contradictions, or majority vote consensus.
Key Components
User Interface (UI/UX Layer)
- Prompt input field
- Final response display
- Toggle for raw model responses, consensus view, or contradictions
- Feedback input (thumbs up/down, comments)
- Prompt Router & Orchestration
Routes user input to multiple LLMs (e.g. LLaMA-3, DeepSeek-R1, Samantha-Mistral) ect - Executes model calls in parallel for speed
- Handles model-specific API formatting via adapters
Aggregation Engine
- Compares outputs semantically and structurally
- Scores responses based on quality, accuracy, and tone
- Synthesises the best ideas into a unified final answer
- Resolves contradictions via logic rules or meta-model
- Meta-Evaluator / Fusion Logic
Uses a separate model or algorithm to rank, merge, and refine the best parts of each model’s response - Can assign confidence scores or tag uncertainty in final output
Knowledge Validation Layer (Optional)
- Verifies key facts using external trusted sources or vector databases
- Optional integration with fact-check APIs or internal truth graphs
Caching & Optimization Layer
- Stores recent queries and results for efficiency
- Reduces redundant calls and cost
Learns from repeated patterns or common questions
System Infrastructure
- API gateway for request handling
- Load balancer for traffic distribution
- Monitoring, logging, and error tracking systems
- Secure compute and data storage
- Feedback & learning loop collects user feedback to improve aggregation logic
- Tracks model accuracy and performance per topic
- Enables adaptive routing based on domain strength (e.g., science to DeepSeek)
Optional UX Features
- “Debate Mode” where models argue points
- “Confidence Heatmap” showing parts of response with weak agreement
- Custom model selection or trust weighting by the user
Benefits
- Accuracy Boost Contradictions can be flagged and corrected via cross-checking.
- Different models may offer culturally or epistemologically distinct views.
- Bias Reduction – No single model dominates the narrative.
- Transparency – Users can see underlying disagreements or blind spots.
- Better Alignment with Truth – Especially useful for complex or controversial questions.
The Challenges
Strategy
Latency
Run model calls in parallel. Cache common results.
Compute Cost
Use smaller models for simpler queries. Apply logic to triage queries.
Tone Harmonization
Apply a final pass model for polishing voice/tone.
Contradictions
Flag them transparently or allow user to choose preferred reasoning.
Future Extensions
Debate Mode LLMs argue points and rebut each other in structured formats.
Confidence Scores – AI shows certainty levels across different models.
Domain-Specific Routing – Direct parts of a question to models best suited for specific domains (e.g., legal, medical, scientific).
User Feedback Loop – Responses improve over time via crowdsourced ranking or expert review.
Target Users
Advanced researchers needing more trustworthy synthesis Journalists, policy analysts, or legal teams wanting multiple perspectives Everyday users who want confidence and clarity from AI
The Vision
Aggregated Intelligence is not just a technical implementation it’s a trust architecture for the next generation of AI. In a world where one model’s word shouldn’t be final, multiple minds are better than one.